
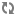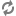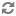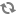
Improving ORC and Parquet Read Performance
Minimize Read and Write Operations for ORC
For optimal performance when reading files saved in the ORC format, read and write operations must be minimized. To achieve this, set the following options:
spark.sql.orc.filterPushdown true
spark.sql.hive.metastorePartitionPruning trueThe spark.sql.orc.filterPushdown option enables the ORC library to skip
unneeded columns and to use index information to filter out parts of the file where it can
be determined that no columns match the predicate.
With the spark.sql.hive.metastorePartitionPruning option enabled,
predicates are pushed down into the Hive metastore to eliminate unmatched partitions.
Minimize Read and Write Operations for Parquet
For optimal performance when reading files saved in the Parquet format, read and write operations must be minimized, including generation of summary metadata, and coalescing metadata from multiple files. The predicate pushdown option enables the Parquet library to skip unneeded columns, saving bandwidth. To achieve this, set the following options:
spark.hadoop.parquet.enable.summary-metadata false
spark.sql.parquet.mergeSchema false
spark.sql.parquet.filterPushdown true
spark.sql.hive.metastorePartitionPruning true