Indexing
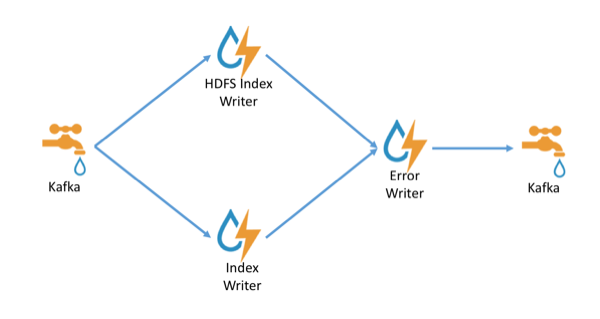
The Indexing topology takes data ingested into Kafka from enriched topologies and sends the data to an indexing bolt configured to write to HDFS and either Elasticsearch or Solr.
Indices are written in batch and the batch size is specified in the enrichment configuration file by the batchSize parameter. This configuration is variable by sensor type.
Errors during indexing are sent to a Kafka topic named
indexing_error.
The following figure illustrates the data flow between Kafka, the Indexing topology, and HDFS: