Example scenario: Safeguarding application datasets on Amazon S3
This scenario describes how a hypothetical retail business uses backups to
safeguard application data and then restore the dataset after failure.
The HBase administration team uses backup sets to store data from a group of tables
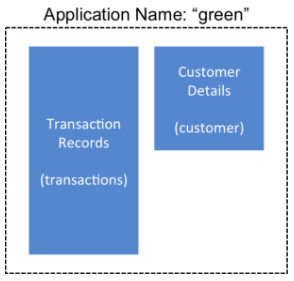
that have interrelated information for an application called
green. In this example, one table contains transaction
records and the other contains customer details. The two tables need to be backed up and
be recoverable as a group.
The admin team also wants to ensure daily backups occur automatically.
Figure 1. Tables Composing the Backup Set
The following is an outline of the steps and examples of commands that are used to
backup the data for the green application and to recover the
data later. All commands are run when logged in as hbase
superuser.
A backup set called green_set is created as an alias
for both the transactions table and the
customer table. The backup set can be used for all
operations to avoid typing each table name. The backup set name is
case-sensitive and should be formed with only printable characters and without
spaces.
$ hbase backup set add green_set transactions
$ hbase backup set add green_set customer
The first backup of green_set data must be a full
backup. The following command example shows how credentials are passed to Amazon
S3 and specifies the file system with the s3a:
prefix.
hbase -D hadoop.security.credential.provider.path=jceks://hdfs@prodhbasebackups/hbase/hbase/s3.jceks backup create full
s3a://green-hbase-backups/ -set green_set
Incremental backups should be run according to a schedule that ensures
essential data recovery in the event of a catastrophe. At this retail company,
the HBase admin team decides that automated daily backups secures the data
sufficiently. The team decides that they can implement this by modifying an
existing Cron job that is defined in /etc/crontab.
Consequently, IT modifies the Cron job by adding the following line:
A catastrophic IT incident disables the production cluster that the
green application uses. An HBase system
administrator of the backup cluster must restore the
green_set dataset to the point in time closest to
the recovery objective.
Note
If the administrator of the backup HBase cluster has the backup ID with relevant details in
accessible records, the following search with the hdfs dfs
-ls command and manually scanning the backup ID list can
be bypassed. Consider continuously maintaining and protecting a detailed
log of backup IDs outside the production cluster in your
environment.
The HBase administrator runs the following command on the directory where
backups are stored to print a list of successful backup IDs on the
console:
hdfs dfs -ls -t s3a://green-hbase-backups/
The admin scans the list to see
which backup was created at a date and time closest to the recovery
objective. To do this, the admin converts the calendar timestamp of the recovery point in time
to Unix time because backup IDs are uniquely identified with Unix time. The backup IDs are listed in reverse chronological order, meaning the
most recent successful backup appears first.
The admin notices that the following line in the command output corresponds
with the green_set backup that needs to be
restored:
s3a://green-hbase-backups//backupId_1467823988425
The admin restores green_set invoking the backup ID and the
-overwrite option. The -overwrite option
truncates all existing data in the destination and populates the tables with
data from the backup dataset. Without this flag, the backup data is appended to
the existing data in the destination. In this case, the admin decides to
overwrite the data because it is corrupted.


 Note
Note