

Hive 3 ACID transactions
Hive 3 achieves atomicity and isolation of operations on transactional tables by using techniques in write, read, insert, create, delete, and update operations that involve delta files, which can provide query status information and help you troubleshoot query problems.
Write and read operations
Hive 3 write and read operations improve the ACID properties and performance of transactional tables. Transactional tables perform as well as other tables. Hive supports all TPC Benchmark DS (TPC-DS) queries.
- Writing to multiple partitions
- Using multiple insert clauses in a single SELECT statement
A single statement can write to multiple partitions or multiple tables. If the operation fails, partial writes or inserts are not visible to users. Operations remain performant even if data changes often, such as one percent per hour. Hive 3 and later does not overwrite the entire partition to perform update or delete operations.
Read semantics consist of snapshot isolation. Hive logically locks in the state of the warehouse when a read operation starts. A read operation is not affected by changes that occur during the operation.
Atomicity and isolation in insert-only tables
When an insert-only transaction begins, the transaction manager gets a transaction ID. For every write, the transaction manager allocates a write ID. This ID determines a path to which data is actually written. The following code shows an example of a statement that creates insert-only transactional table:
CREATE TABLE tm (a int, b int) TBLPROPERTIES
('transactional'='true', 'transactional_properties'='insert_only')Assume that three insert operations occur, and the second one fails:
INSERT INTO tm VALUES(1,1);
INSERT INTO tm VALUES(2,2); // Fails
INSERT INTO tm VALUES(3,3);For every write operation, Hive creates a delta directory to which the transaction manager writes data files. Hive writes all data to delta files, designated by write IDs, and mapped to a transaction ID that represents an atomic operation. If a failure occurs, the transaction is marked aborted, but it is atomic:
tm
___ delta_0000001_0000001_0000
└── 000000_0
___ delta_0000002_0000002_0000 //Fails
└── 000000_0
___ delta_0000003_0000003_0000
└── 000000_0During the read process, the transaction manager maintains the state of every transaction. When the reader starts, it asks for the snapshot information, represented by a high watermark. The watermark identifies the highest transaction ID in the system followed by a list of exceptions that represent transactions that are still running or are aborted.
The reader looks at deltas and filters out, or skips, any IDs of transactions that are aborted or still running. The reader uses this technique with any number of partitions or tables that participate in the transaction to achieve atomicity and isolation of operations on transactional tables.
Atomicity and isolation in CRUD tables
You can create a full CRUD (create, retrieve, update, delete) transactional table using the following SQL statement:
CREATE TABLE acidtbl (a INT, b STRING); Running SHOW CREATE TABLE acidtbl provides information about the defaults:
transactional (ACID) and the ORC data storage format:
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE TABLE `acidtbl`( |
| `a` int, |
| `b` string) |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' |
| STORED AS INPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' |
| LOCATION |
| 'hdfs://myserver.com:8020/warehouse/tablespace/managed/hive/acidtbl' |
| TBLPROPERTIES ( |
| 'bucketing_version'='2', |
| 'transactional'='true', |
| 'transactional_properties'='default', |
| 'transient_lastDdlTime'='1555090610') |
+----------------------------------------------------+
Tables that support updates and deletions require a slightly different technique to achieve atomicity and isolation. Hive runs on top of an append-only file system, which means Hive does not perform in-place updates or deletions. Isolation of readers and writers cannot occur in the presence of in-place updates or deletions. In this situation, a lock manager or some other mechanism, is required for isolation. These mechanisms create a problem for long-running queries.
struct that consists of the following information: - The write ID that maps to the transaction that created the row
- The bucket ID, a bit-backed integer with several bits of information, of the physical writer that created the row
- The row ID, which numbers rows as they were written to a data file
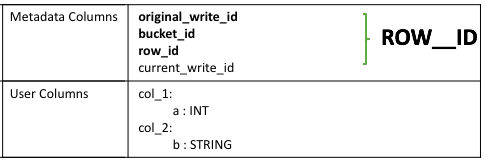
Instead of in-place deletions, Hive appends changes to the table when a deletion occurs. The deleted data becomes unavailable and the compaction process takes care of the garbage collection later.
Create operation
The following example inserts several rows of data into a full CRUD transactional table, creates a delta file, and adds row IDs to a data file.
INSERT INTO acidtbl (a,b) VALUES (100, "oranges"), (200, "apples"), (300, "bananas");| ROW_ID | a | b |
|---|---|---|
| {1,0,0} | 100 | "oranges" |
| {1,0.1} | 200 | "apples" |
| {1,0,2} | 300 | "bananas" |
Delete operation
A delete statement that matches a single row also creates a delta file, called the delete-delta. The file stores a set of row IDs for the rows that match your query. At read time, the reader looks at this information. When it finds a delete event that matches a row, it skips the row and that row is not included in the operator pipeline. The following example deletes data from a transactional table:
DELETE FROM acidTbl where a = 200;| ROW_ID | a | b |
|---|---|---|
| {1,0,1} | null | null |
Update operation
An update combines the deletion and insertion of new data. The following example updates a transactional table:
UPDATE acidTbl SET b = "pears" where a = 300;One delta file contains the delete event, and the other, the insert event:
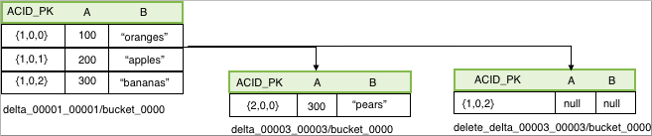
The reader, which requires the AcidInputFormat, applies all the insert events and encapsulates all the logic to handle delete events. A read operation first gets snapshot information from the transaction manager based on which it selects files that are relevant to that read operation. Next, the process splits each data file into the number of pieces that each process has to work on. Relevant delete events are localized to each processing task. Delete events are stored in a sorted ORC file. The compressed, stored data is minimal, which is a significant advantage of Hive 3. You no longer need to worry about saturating the network with insert events in delta files.