You can perform interactive analytic queries on real-time and historical data using the
HDP integration of Hive and Apache Druid (incubating). You can discover existing Druid data
sources as external tables, create or ingest batch data into Druid, set up Druid-Kafka streaming
ingestion using Hive, and query Druid data sources from Hive.
The integration of Hive with Druid places a SQL layer on Druid. After Druid ingests data from a
Hive enterprise data warehouse (EDW), the interactive and sub-second query capabilities of Druid
can be used to accelerate queries on historical data from the EDW. Hive integration with Druid
enables applications such as Tableau to scale while queries run concurrently on both real-time
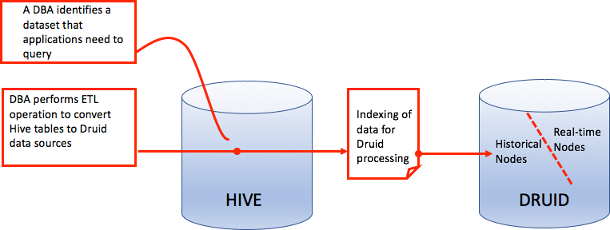
and historical data. The following figure is an overview of how Hive historical data can be
brought into a Druid environment. Queries analyzing Hive-sourced data are run directly on the
historical nodes of Druid after indexing between the two databases completes.