Workload management
As administrator, you manage workloads by creating resource plans to improve parallel query execution and cluster sharing of queries using low-latency analytical processing (LLAP).
The resource plan is a self-contained, resource-sharing configuration. One resource plan is active on the cluster at a time. Typically, enabling and disabling a resource plan on a live cluster does not affect running queries. You, as administrator, or your script can apply resource plans that configure the cluster for different situations. For example, your script can apply a resource plan that configures the cluster to handle high traffic. When traffic decreases, you can switch the resource plan to support traffic for interactive data visualization, deep ad-hoc analytics, and large-scale BI reporting.
You can create a resource plan to meet a defined data processing benchmark when a workload reaches a high volume of concurrent queries. For example, consider an enterprise that has an ad-hoc analytics application exposed to around 100 analysts. Data set and query patterns dictate that a generated query executes within a few seconds. A resource plan can ensure that when up to 100 users might concurrently use the system, at least 95 percent of queries complete in fewer than 15 seconds.
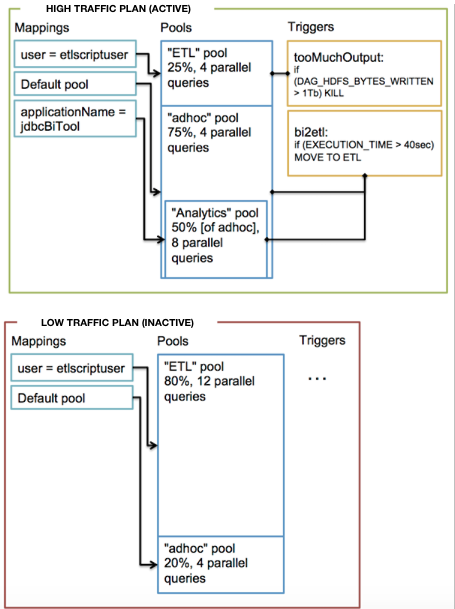
A resource plan can consist of one or more query pools, mappings, and triggers:
- A query pool shares resources with LLAP cluster processes and queries within the pool, and sets the maximum concurrent queries.
- A mapping routes incoming queries to pools based on specified factors, such as user name, group, or application.
- A trigger initiates an action, such as killing queries in a pool or all queries running in a cluster, based on query metrics represented by Apache Hadoop, Tez, and Hive counters.