A typical Hadoop cluster is comprised of masters, slaves and clients.
Hadoop and HBase clusters have two types of machines:
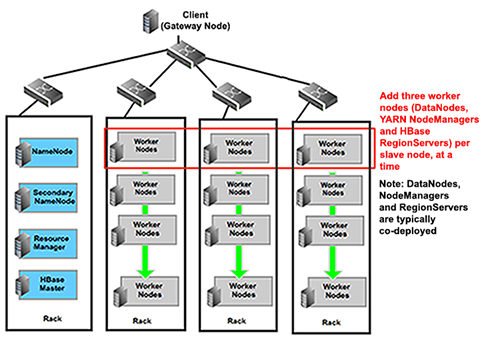
Masters (HDFS NameNode, MapReduce JobTracker (HDP-1) or YARN ResourceManager (HDP-2), and HBase Master
Slaves (the HBase RegionServers; HDFS DataNodes, MapReduce TaskTrackers in HDP-1; and YARN NodeManagers in HDP-2). The DataNodes, TaskTrackers/NodeManagers, and HBase RegionServers are co-located or co-deployed to optimize the locality of data that will be accessed frequently.
Hortonworks recommends separating master and slave nodes because task/application workloads on the slave nodes should be isolated from the masters. Slave nodes are frequently decommissioned for maintenance.
For evaluation purposes, it is possible to deploy Hadoop on a single node, with all master and the slave processes reside on the same machine. However, it's more common to configure a small cluster of two nodes, with one node acting as master (running both NameNode and JobTracker/ResourceManager) and the other node acting as the slave (running DataNode and TaskTracker/NodeMangers).
The smallest cluster can be deployed using a minimum of four machines, with one machine deploying all the master processes, and the other three co-deploying all the slave nodes (YARN NodeManagers, DataNodes, and RegionServers). Clusters of three or more machines typically use a single NameNode and JobTracker/ResourceManager with all the other nodes as slave nodes.
Typically, a medium-to-large Hadoop cluster consists of a two- or three-level architecture built with rack-mounted servers. Each rack of servers is interconnected using a 1 Gigabit Ethernet (GbE) switch. Each rack-level switch is connected to a cluster-level switch, which is typically a larger port-density 10GbE switch. These cluster-level switches may also interconnect with other cluster-level switches or even uplink to another level of switching infrastructure.
To maintain the replication factor of three, a minimum of three machines is required per slave node.
For further information, see Data Replication in Apache Hadoop.
To access Hortonworks' "Hadoop Cluster Size-O-Tron", go to http://www.hortonworks.com/resources/cluster-sizing-guide/.