Writing Storm applications requires an understanding of the following basic concepts:
Table 2.1. Storm Concepts
| Storm Concept | Description |
|---|---|
| Tuple | A named list of values of any data type. The native data structure used by Storm. |
| Stream | An unbounded sequence of tuples. |
| Spout | Generates a stream from a realtime data source. |
| Bolt | Contains data processing, persistence, and messaging alert logic. Can also emit tuples for downstream bolts. |
| Stream Grouping | Controls the routing of tuples to bolts for processing. |
| Topology | A group of spouts and bolts wired together into a workflow. A Storm application. |
| Processing Reliability | Storm guarantee about the delivery of tuples in a topology. |
| Workers | A Storm process. A worker may run one or more executors. |
| Executors | A Storm thread launched by a Storm worker. An executor may run one or more tasks. |
| Tasks | A Storm job from a spout or bolt. |
| Process Controller | Monitors and restarts failed Storm processes. Examples include
supervisord, monit, and
daemontools. |
| Master/Nimbus Node | The host in a multi-node Storm cluster that runs a process
controller, such as supervisord, and the Storm nimbus,
ui, and other related daemons. The process controller is responsible
for restarting failed process controller daemons, such as
supervisor, on slave nodes. The Storm nimbus daemon
is responsible for monitoring the Storm cluster and assigning tasks
to slave nodes for execution. |
| Slave Node | A host in a multi-node Storm cluster that runs a process
controller daemon, such as supervisor, as well as the
worker processes that run Storm topologies. The process controller
daemon is responsible for restarting failed worker
processes. |
Spout
All spouts must implement the backtype.storm.topology.IRichSpout
interface from the storm core API. BaseRichSpout is the most basic
implementation, but there are several others, including ClojureSpout,
DRPCSpout, and FeederSpout. In addition, Hortonworks
provides a Kafka Spout to ingest data from a Kafka cluster.
The following example, RandomSentenceSpout, is included with the
storm-starter connector installed with Storm at
/usr/lib/storm/contrib/storm-starter.
package storm.starter.spout;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
public class RandomSentenceSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
Random _rand;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
}
@Override
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{ "the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature" };
String sentence = sentences[_rand.nextInt(sentences.length)];
_collector.emit(new Values(sentence));
}
@Override
public void ack(Object id) {
}
@Override
public void fail(Object id) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
Bolt
All bolts must implement the IRichBolt interface.
BaseRichBolt is the most basic implementation , but there are several
others, including BatchBoltExecutor, ClojureBolt, and
JoinResult.
The following example, TotalRankingsBolt.java, is included with
storm-starter and installed with Storm at
/usr/lib/storm/contrib/storm-starter.
package storm.starter.bolt;
import backtype.storm.tuple.Tuple;
import org.apache.log4j.Logger;
import storm.starter.tools.Rankings;
/**
* This bolt merges incoming {@link Rankings}.
* <p/>
* It can be used to merge intermediate rankings generated by {@link IntermediateRankingsBolt} into a final,
* consolidated ranking. To do so, configure this bolt with a globalGrouping on {@link IntermediateRankingsBolt}.
*/
public final class TotalRankingsBolt extends AbstractRankerBolt {
private static final long serialVersionUID = -8447525895532302198L;
private static final Logger LOG = Logger.getLogger(TotalRankingsBolt.class);
public TotalRankingsBolt() {
super();
}
public TotalRankingsBolt(int topN) {
super(topN);
}
public TotalRankingsBolt(int topN, int emitFrequencyInSeconds) {
super(topN, emitFrequencyInSeconds);
}
@Override
void updateRankingsWithTuple(Tuple tuple) {
Rankings rankingsToBeMerged = (Rankings) tuple.getValue(0);
super.getRankings().updateWith(rankingsToBeMerged);
super.getRankings().pruneZeroCounts();
}
@Override
Logger getLogger() {
return LOG;
}
}
Stream Grouping
Stream grouping allows Storm developers to control how tuples are routed to bolts in a workflow. The following table describes the stream groupings available.
Table 2.2. Stream Groupings
| Stream Grouping | Description |
|---|---|
| Shuffle | Sends tuples to bolts in random, round robin sequence. Use for atomic operations, such as math. |
| Fields | Sends tuples to a bolt based on one or more fields in the tuple. Use to segment an incoming stream and to count tuples of a specified type. |
| All | Sends a single copy of each tuple to all instances of a receiving bolt. Use to send a signal, such as clear cache or refresh state, to all bolts. |
| Custom | Customized processing sequence. Use to get maximum flexibility of topology processing based on factors such as data types, load, and seasonality. |
| Direct | Source decides which bolt receives a tuple. |
| Global | Sends tuples generated by all instances of a source to a single target instance. Use for global counting operations. |
Storm developers specify the field grouping for each bolt using methods on the
TopologyBuilder.BoltGetter inner class, as shown in the following
excerpt from the the WordCountTopology.java example included with
storm-starter.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
The first bolt uses shuffle grouping to split random sentences generated with the
RandomSentenceSpout. The second bolt uses fields grouping to segment
and perform a count of individual words in the sentences.
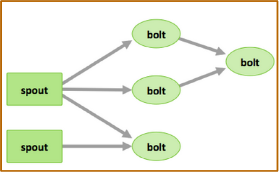
Topology
The following image depicts a Storm topology with a simple workflow.
The TopologyBuilder class is the starting point for quickly writing Storm
topologies with the storm-core API. The class contains getter and setter
methods for the spouts and bolts that comprise the streaming data workflow, as shown in
the following sample code.
...
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout1", new BaseRichSpout());
builder.setSpout("spout2", new BaseRichSpout());
builder.setBolt("bolt1", new BaseBasicBolt());
builder.setBolt("bolt2", new BaseBasicBolt());
builder.setBolt("bolt3", new BaseBasicBolt());
...
Processing Guarantees
Storm provides two types of guarantee about the processing of tuples for a Storm topology.
Table 2.3. Processing Guarantee
| Guarantee | Description |
|---|---|
| At least once | Reliable; Tuples are processed at least once, but may be processed more than once. Use when subsecond latency is required and for unordered idempotent operations. |
| Exactly once | Reliable; Tuples are processed only once. Requires the use of a Trident spout and the Trident API. |
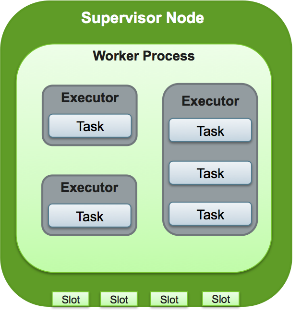
Workers, Executors, and Tasks
Apache Storm processes, called workers, run on predefined ports on the machine hosting Storm. Each worker process may run one or more executors, or threads, where each executor is a thread spawned by the worker process. Each executor runs one or more tasks from the same component, where a component is a spout or bolt from a topology.
See the Storm javadocs at http://storm.incubator.apache.org/apidocs/ for more information.