

Configuring Storm Resource Usage
The following settings can be useful for tuning Storm topologies in production environments.
Instructions are for a cluster managed by Ambari. For clusters that are not managed by
Ambari, update the property in its configuration file; for example, update the value of
topology.message.timeout.secs in the storm.yaml
configuration file. (Do not update files manually if your cluster is managed by
Ambari.)
Memory Allocation
- Worker process max heap size:
worker.childopts -XmXoption -
Maximum JVM heap size for the worker JVM. The default Ambari value is 768 MB. On a production system, this value should be based on workload and machine capacity. If you observe out-of-memory errors in the log, increase this value and fine tune it based on throughput; 1024 MB should be a reasonable value to start with.
To set maximum heap size for the worker JVM, navigate to the "Advanced storm-site" category and append the
-Xmxoption to worker.childopts setting. The following option sets maximum heap size to 1 GB:-Xmx1024m - Logviewer process max heap size:
logviewer.childopts -Xmxoption -
Maximum JVM heap size for the logviewer process. The default is 128 MB. On production machines you should consider increasing the
logviewer.childopts -Xmxoption to 768 MB or more (1024 MB should be a sufficient for an upper-end value).
Message Throughput
-
topology.max.spout.pending -
Maximum number of messages that can be pending in a spout at any time. The default is null (no limit).
The setting applies to all core Storm and Trident topologies in a cluster:
-
For core Storm, this value specifies the maximum number of tuples that can be pending: tuples that have been emitted from a spout but have not been acked or failed yet.
-
For Trident, which process batches in core, this property specifies the maximum number of batches that can be pending.
If you expect bolts to be slow in processing tuples (or batches) and you do not want internal buffers to fill up and temporarily stop emitting tuples to downstream bolts, you should set
topology.max.spout.pendingto a starting value of 1000 (for core Storm) or a value of 1 (for Trident), and increase the value depending on your throughput requirements.You can override this value for a specific topology when you submit the topology. The following example restricts the number of pending tuples to 100 for a topology:
$ storm jar -c topology.max.spout.pending=100 jar args...If you plan to use windowing functionality, set this value to null, or increase it to cover the estimated maximum number of active tuples in a single window. For example, if you define a sliding window with a duration of 10 minutes and a sliding interval of 1 minute, set
topology.max.spout.pendingto the maximum number of tuples that you expect to receive within an 11-minute interval.This setting has no effect on spouts that do not anchor tuples while emitting.
-
-
topology.message.timeout.secs -
Maximum amount of time given to the topology to fully process a tuple tree from the core-storm API, or a batch from the Trident API, emitted by a spout. If the message is not acked within this time frame, Storm fails the operation on the spout. The default is 30 seconds.
If you plan to use windowing functionality, set this value based on your windowing definitions. For example, if you define a 10 minute sliding window with a 1 minute sliding interval, you should set this value to at least 11 minutes.
You can also set this value at the topology level when you submit a topology; for example:
$ storm jar -c topology.message.timeout.secs=660 jar args...
Nimbus Node Resources
-
nimbus.thrift.max_buffer_size -
Maximum buffer size that the Nimbus Thrift server allocates for servicing requests. The default is 1 MB. If you plan to submit topology files larger than 100 MB, consider increasing this value.
-
nimbus.thrift.threads -
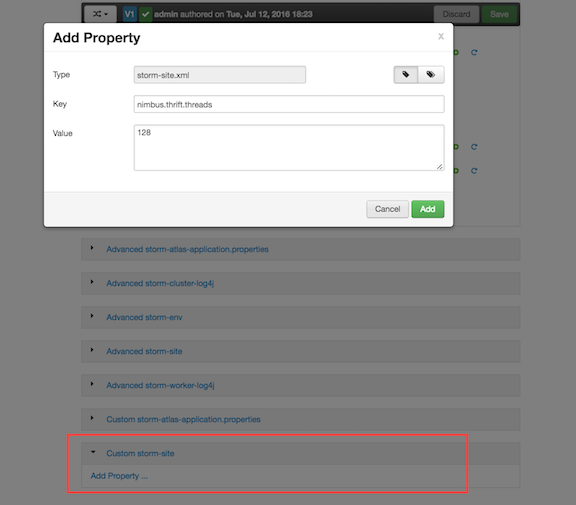
Number of threads to be used by the Nimbus Thrift server. The default is 64 threads. If you have more than ten hosts in your Storm cluster, consider increasing this value to a minimum of 196 threads, to handle the workload associated with multiple workers making multiple requests on each host.
You can set this value by adding the property and its value in the Custom storm-site category, as shown in the following graphic:
Number of Workers on a Supervisor Node
-
supervisor.slots.ports -
List of ports that can run workers on a supervisor node. The length of this list defines the number of workers that can be run on a supervisor node; there is one communication port per worker.
Use this configuration to tune how many workers to run on each machine. Adjust the value based on how many resources each worker will consume, based on the topologies you will submit (as opposed to machine capacity).
Number of Event Logger Tasks
-
topology.eventlogger.executors -
Number of event logger tasks created for topology event logging. The default is 0; no event logger tasks are created.
If you enable topology event logging, you must set this value to a number greater than zero, or to
null:-
topology.eventlogger.executors: <n>createsnevent logger tasks for the topology. A value of 1 should be sufficient to handle most event logging use cases. -
topology.eventlogger.executors: nullcreates one event logger task per worker. This is only needed if you plan to use a high sampling percentage, such as logging all tuples from all spouts and bolts.
-
Storm Metadata Directory
-
storm.local.dir -
Local directory where Storm daemons store topology metadata. You need not change the default value, but if you do change it, set it to a durable directory (not a directory such as /tmp).