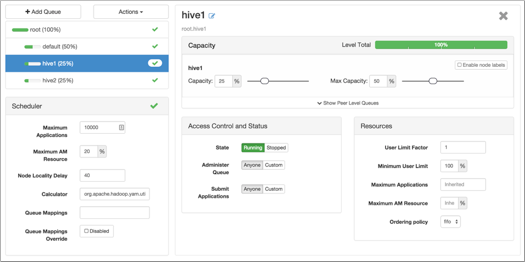
Configure a queue for batch processing
You can configure the capacity scheduler queues to scale a Hive batch job for your environment. YARN uses the queues to allocate Hadoop cluster resources among users and groups.
In this task, you create queues and set up a capacity scheduler to separate short- and long-running queries into the queues:
- hive1
- This queue is used for short-duration queries and is assigned 50 percent of cluster resources.
- hive2
- This queue is used for longer-duration queries and is assigned 50 percent of cluster resources.
-
Configure usage limits for these queues and their users.
For example:
yarn.scheduler.capacity.root.hive1.maximum-capacity=50 yarn.scheduler.capacity.root.hive2.maximum-capacity=50 yarn.scheduler.capacity.root.hive1.user-limit=1 yarn.scheduler.capacity.root.hive2.user-limit=1The default value of 1 for user-limit means that any single user in the queue can at a maximum occupy 1X the queue's configured capacity. These settings prevent users in one queue from monopolizing resources across all queues in a cluster.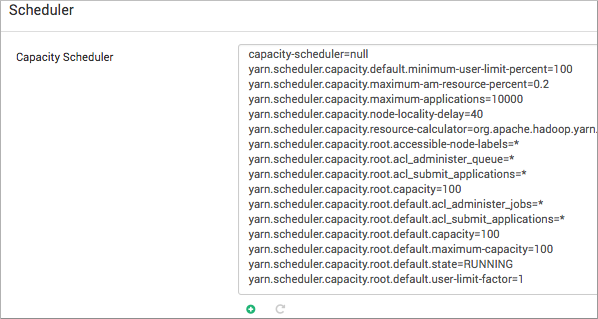
-
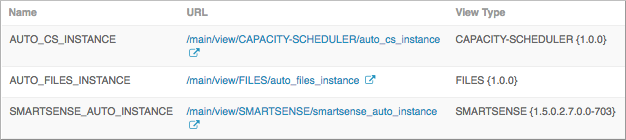
From the Ambari dashboard, select .
-
Click the URL for the view named AUTO_CS_INSTANCE, which is the capacity scheduler
view.
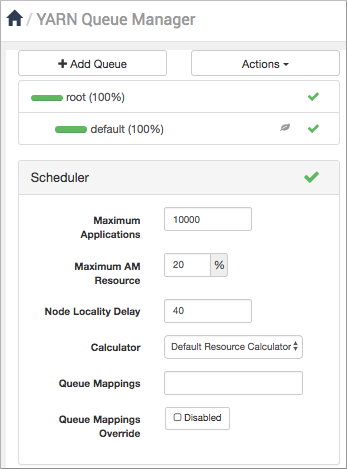
-
In the YARN Queue Manager, click Add Queue.
-
To create the following schedule, select the
rootqueue and addhive1andhive2at that level: