Configure a Superset visualization
In Apache Ambari, after connecting Apache Superset to Apache Hive, you can configure visualizations, such as aggregations, slices of data, or plotted data to better understand the data.
CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3,2));- You created and populated a table in the Hive warehouse.
-
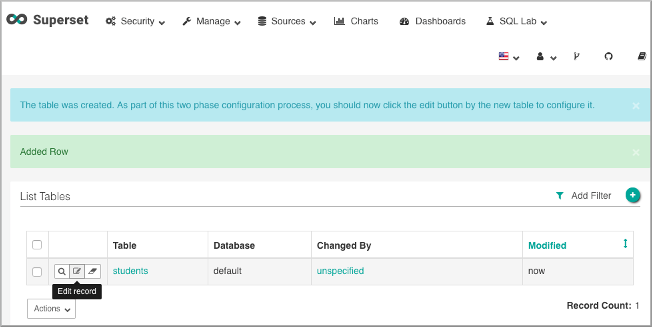
On List Tables, click Edit Record:
-
On the Detail tab of Edit Table, in Table Name, enter the name of a table in
the Hive database.
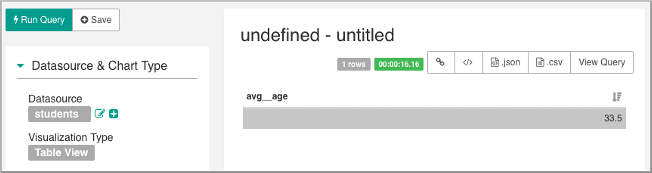
A table visualization appears, showing an aggregation calculated automatically by Superset: average age 33.5 in this example: