You use Apache Ambari to add Apache Druid (incubating) to your cluster.
-
On the Ambari host, download the database connector that matches your
database.
For MySQL, on Centos 7.4 for
example:
yum install mysql-connector-java*
The database is installed in /usr/share/java.
-
On the Ambari server node, run the command to set up the connector, which
includes the path to the downloaded JAR. For MySQL, on Centos 7.4 for
example:
ambari-server setup --jdbc-db=mysql
--jdbc-driver=/usr/share/java/mysql-connector-java.jar
-
Start Ambari, and in Ambari select Services > Add Service.
-
Select Druid, and click Next.
-
In Assign Masters, typically you can accept the defaults to put the Broker,
Coordinator, Overload, and Router components on the same master node, and click
Next.
-
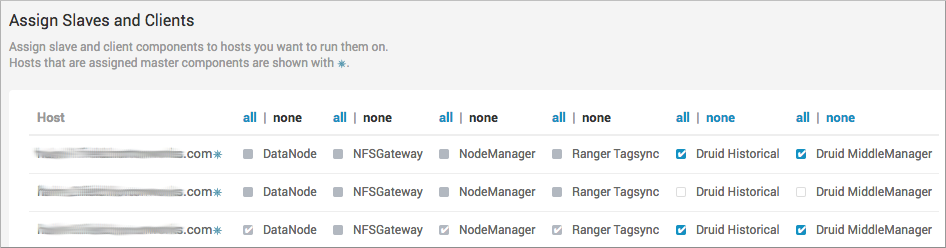
In Assign Slaves and Clients, putting Druid Historical and Druid MiddleManager
on the same nodes and running these co-located components on additional nodes is
recommended.