Trident State
Trident includes high-level abstractions for managing persistent state in a topology. State management is fault tolerant: updates are idempotent when failures and retries occur. These properties can be combined to achieve exactly-once processing semantics. Implementing persistent state with the Storm core API would be more difficult.
Trident groups tuples into batches, each of which is given a unique transaction ID. When a batch is replayed, the batch is given the same transaction ID. State updates in Trident are ordered such that a state update for a particular batch will not take place until the state update for the previous batch is fully processed. This is reflected in Tridents State interface at the center of the state management API:
public interface State {
void beginCommit(Long txid);
void commit(Long txid);
}When updating state, Trident informs the State implementation that a
transaction is about to begin by calling beginCommit(), indicating that
state updates can proceed. At that point the State implementation
updates state as a batch operation. Finally, when the state update is complete,
Trident calls the commit() method, indicating that the state update is
ending. The inclusion of transaction ID in both methods allows the underlying
implementation to manage any necessary rollbacks if a failure occurs.
Implementing Trident states against various data stores is beyond the scope of this document, but more information can be found in the Trident State documentation(https://storm.apache.org/releases/1.0.1/Trident-state.html).
Trident Spouts
Trident defines three spout types that differ with respect to batch content, failure response, and support for exactly-once semantics:
- Non-transactional spouts
Non-transactional spouts make no guarantees for the contents of each batch. As a result, processing may be at-most-once or at least once. It is not possible to achieve exactly-once processing when using non-transactional Trident spouts.
- Transactional spouts
Transactional spouts support exactly-once processing in a Trident topology. They define success at the batch level, and have several important properties that allow them to accomplish this:
Batches with a given transaction ID are always identical in terms of tuple content, even when replayed.
Batch content never overlaps. A tuple can never be in more than one batch.
Tuples are never skipped.
With transactional spouts, idempotent state updates are relatively easy: because batch transaction IDs are strongly ordered, the ID can be used to track data that has already been persisted. For example, if the current transaction ID is 5 and the data store contains a value for ID 5, the update can be safely skipped.
- Opaque transactional spouts
Opaque transactional spouts define success at the tuple level. Opaque transactional spouts have the following properties:
There is no guarantee that a batch for a particular transaction ID is always the same.
Each tuple is successfully processed in exactly one batch, though it is possible for a tuple to fail in one batch and succeed in another.
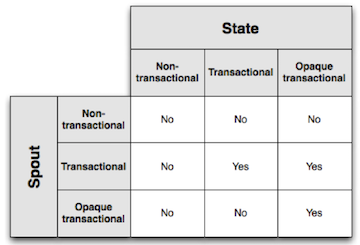
The difference in focus between transactional and opaque transactional spouts—success at the batch level versus the tuple level, respectively—has key implications in terms of achieving exactly-once semantics when combining different spouts with different state types.
Achieving Exactly-Once Messaging in Trident
As mentioned earlier, achieving exactly-once semantics in a Trident topology require certain combinations of spout and state types. It should also be clear why exactly-once guarantees are not possible with non-transactional spouts and states. The table below illustrates which combinations of spouts and states support exactly-once processing: