
Using Spark Streaming
Spark Streaming is an extension of the core spark package. Using Spark
Streaming, your applications can ingest data from sources such as Apache Kafka and Apache Flume;
process the data using complex algorithms expressed with high-level functions like
map, reduce, join, and window; and send
results to file systems, databases, and live dashboards.
Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches:
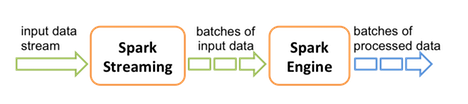
See the Apache Spark Streaming Programming Guide for conceptual information; programming examples in Scala, Java, and Python; and performance tuning recommendations.
Apache Spark 1.6 has built-in support for the Apache Kafka 08 API. If you want to access a Kafka 0.10 cluster using new Kafka 0.10 APIs (such as wire encryption support) from Spark 1.6 streaming jobs, the spark-kafka-0-10-connector package supports a Kafka 0.10 connector for Spark 1.x streaming. See the package readme file for additional documentation.
The remainder of this subsection describes general steps for developers using Spark
Streaming with Kafka on a Kerberos-enabled cluster; it includes a sample pom.xml
file for Spark Streaming applications with Kafka. For additional examples, see the Apache
GitHub example repositories for Scala, Java, and Python.
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
Dynamic Resource Allocation does not work with Spark Streaming. |
Prerequisites
Before running a Spark Streaming application, Spark and Kafka must be deployed on the cluster.
Unless you are running a job that is part of the Spark examples package installed by Hortonworks Data Platform (HDP), you must add or retrieve the HDP spark-streaming-kafka .jar file and associated .jar files before running your Spark job.
Building and Running a Secure Spark Streaming Job
Depending on your compilation and build processes, one or more of the following tasks might be required before running a Spark Streaming job:
If you are using
mavenas a compile tool:Add the Hortonworks repository to your
pom.xmlfile:<repository> <id>hortonworks</id> <name>hortonworks repo</name> <url>http://repo.hortonworks.com/content/repositories/releases/</url> </repository>Specify the Hortonworks version number for Spark streaming Kafka and streaming dependencies to your
pom.xmlfile:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.6.3.2.4.2.0-90</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.6.3.2.4.2.0-90</version> <scope>provided</scope> </dependency>Note that the correct version number includes the Spark version and the HDP version.
(Optional) If you prefer to pack an uber .jar rather than use the default ("provided"), add the
maven-shade-pluginto yourpom.xmlfile:<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> </execution> </executions> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <finalName>uber-${project.artifactId}-${project.version}</finalName> </configuration> </plugin>
Instructions for submitting your job depend on whether you used an uber .jar file or not:
If you kept the default .jar scope and you can access an external network, use
--packagesto download dependencies in the runtime library:spark-submit --master yarn-client \ --num-executors 1 \ --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.3.2.4.2.0-90 \ --repositories http://repo.hortonworks.com/content/repositories/releases/ \ --class <user-main-class> \ <user-application.jar> \ <user arg lists>The artifact and repository locations should be the same as specified in your
pom.xmlfile.If you packed the .jar file into an uber .jar, submit the .jar file in the same way as you would a regular Spark application:
spark-submit --master yarn-client \ --num-executors 1 \ --class <user-main-class> \ <user-uber-application.jar> \ <user arg lists>
For a sample pom.xml file, see Sample pom.xml file for Spark Streaming with Kafka.
Running Spark Streaming Jobs on a Kerberos-Enabled Cluster
To run a Spark Streaming job on a Kerberos-enabled cluster, complete the following steps:
Select or create a user account to be used as principal.
This should not be the
kafkaorsparkservice account.Generate a keytab for the user.
Create a Java Authentication and Authorization Service (JAAS) login configuration file: for example,
key.conf.Add configuration settings that specify the user keytab.
The keytab and configuration files are distributed using YARN local resources. Because they reside in the current directory of the Spark YARN container, you should specify the location as
./v.keytab.The following example specifies keytab location
./v.keytabfor principalvagrant@example.com:KafkaClient { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="v.keytab" storeKey=true useTicketCache=false serviceName="kafka" principal="vagrant@EXAMPLE.COM"; };In your
spark-submitcommand, pass the JAAS configuration file and keytab as local resource files, using the--filesoption, and specify the JAAS configuration file options to the JVM options specified for the driver and executor:spark-submit \ --files key.conf#key.conf,v.keytab#v.keytab \ --driver-java-options "-Djava.security.auth.login.config=./key.conf" \ --conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./key.conf" \ ...Pass any relevant Kafka security options to your streaming application.
For example, the KafkaWordCount example accepts PLAINTEXTSASL as the last option in the command line:
KafkaWordCount /vagrant/spark-examples.jar c6402:2181 abc ts 1 PLAINTEXTSASL
Sample pom.xml File for Spark Streaming with Kafka
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>test</groupId>
<artifactId>spark-kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>hortonworks</id>
<name>hortonworks repo</name>
<url>http://repo.hortonworks.com/content/repositories/releases/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.3.2.4.2.0-90</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.3.2.4.2.0-90</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<defaultGoal>package</defaultGoal>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/test/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<goals>
<goal>copy-resources</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<recompileMode>incremental</recompileMode>
<args>
<arg>-target:jvm-1.7</arg>
</args>
<javacArgs>
<javacArg>-source</javacArg>
<javacArg>1.7</javacArg>
<javacArg>-target</javacArg>
<javacArg>1.7</javacArg>
</javacArgs>
</configuration>
<executions>
<execution>
<id>scala-compile</id>
<phase>process-resources</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<finalName>uber-${project.artifactId}-${project.version}</finalName>
</configuration>
</plugin>
</plugins>
</build>
</project>