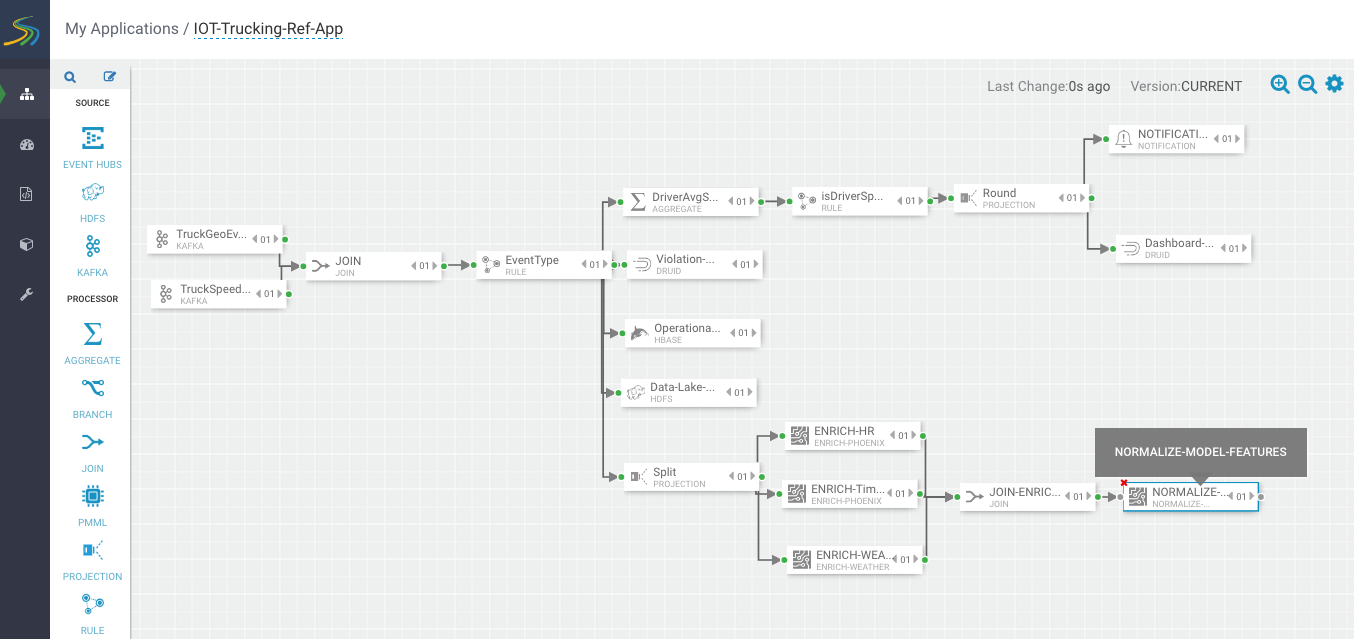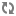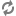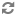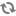
Streaming Split Join Pattern
About This Task
You objective is to perform three enrichments:
Retrieve a driver's certification and wage plan from the driver's table
Retrieve the driver's hours and miles logged from the timesheet table
Query weather information for a specific time and location.
To do this, use the split join pattern to split the stream into 3, perform the enrichment in parallel, and then re-join the three streams.
Steps for Creating a Split Join Key
Create a new split key in the stream which allows you to join in a common field when you join the three stream. To do this, drag the projection processor to the canvas and create a connection from the EventType rule processor to this projectioin processor. When configuring the connection, select the Non Violation Events Rule which tells SAM to only send non violation events to this project processor.
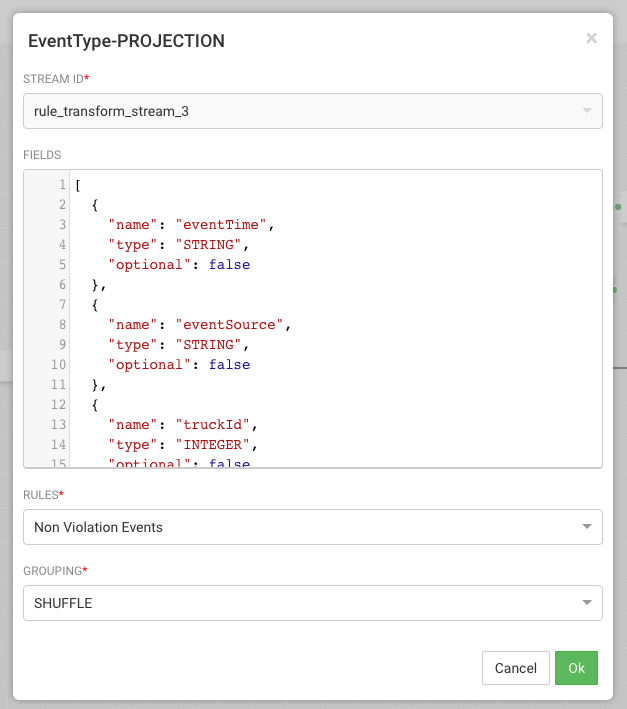
Configure the projection processor to create our split join key called splitJoinValue using the custom udf we uploaded earlier called "TIMESTAMP_LONG". We will also do a transformation which calculates the week based on the event time which is required for one of the enrichments downstream. Configure the processor like the following:
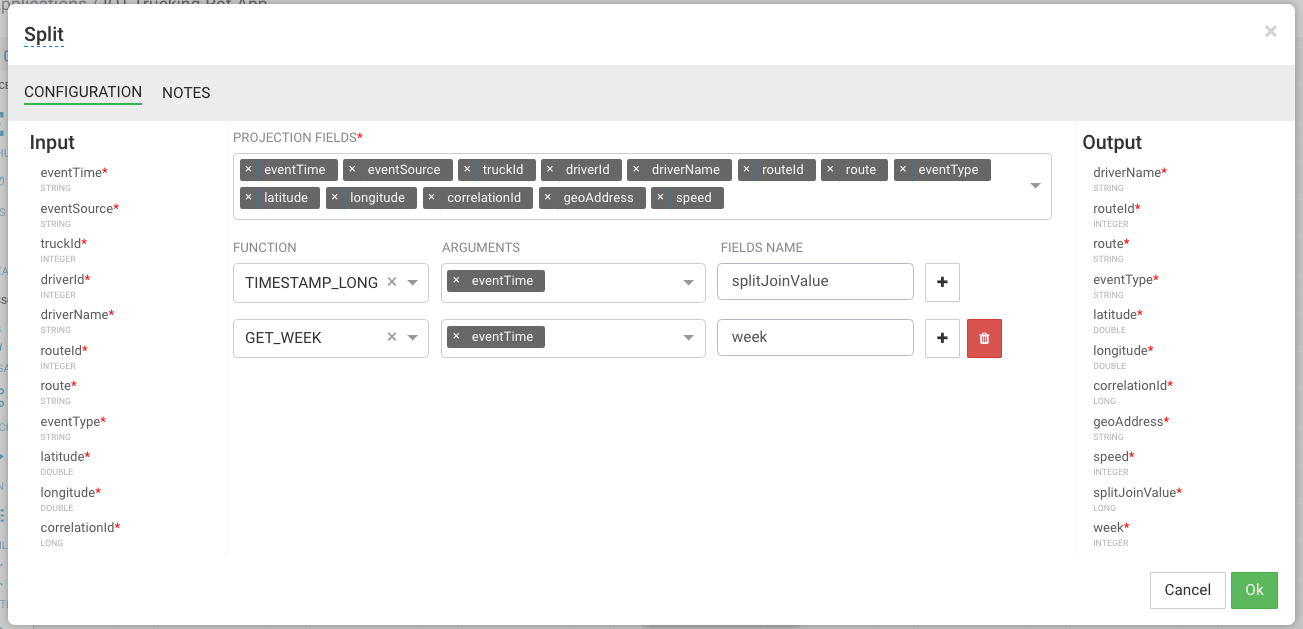
Steps for Splitting the Stream into Three to Perform Enrichments in Parallel
With the split join key created, we can split the stream into three to perform the enrichments in parallel. To do the first split to do the enrichment of the wage and certification status of driver, drag the "ENRICH-PHOENIX" processor the canvas and connect it from the Split project processor
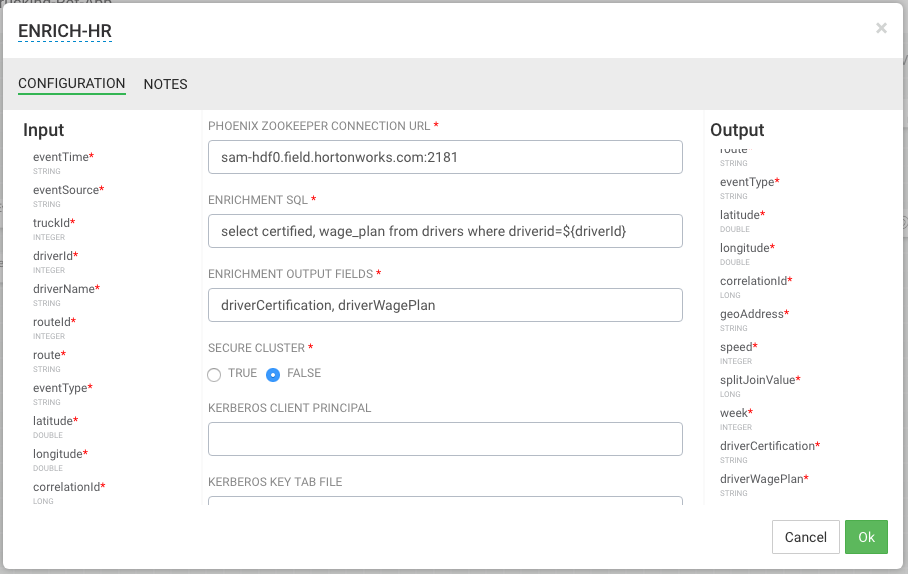
Configure the enrich processor like below. After this processor executes, the output schema will have two fields populated called driverCertification and driverWagePlan.
ENRICHEMNT SQL: select certified, wage_plan from drivers where driverid=${driverId}
ENRICHMENT OUTPUT FIELDS: driverCertification, driverWagePlan
SECURE CLUSTER: false
INPUT SCHEMA MAPPINGS: Leave defaults
OUTPUT FIELDS: select all fields except for driverFatigueByHours and driverFatigueByMiles
Create the second stream to do enrichment of the drivers hours and miles logged in last week by dragging another "ENRICH-PHOENIX" processor to the canvas and connect it from the Split projection processor.
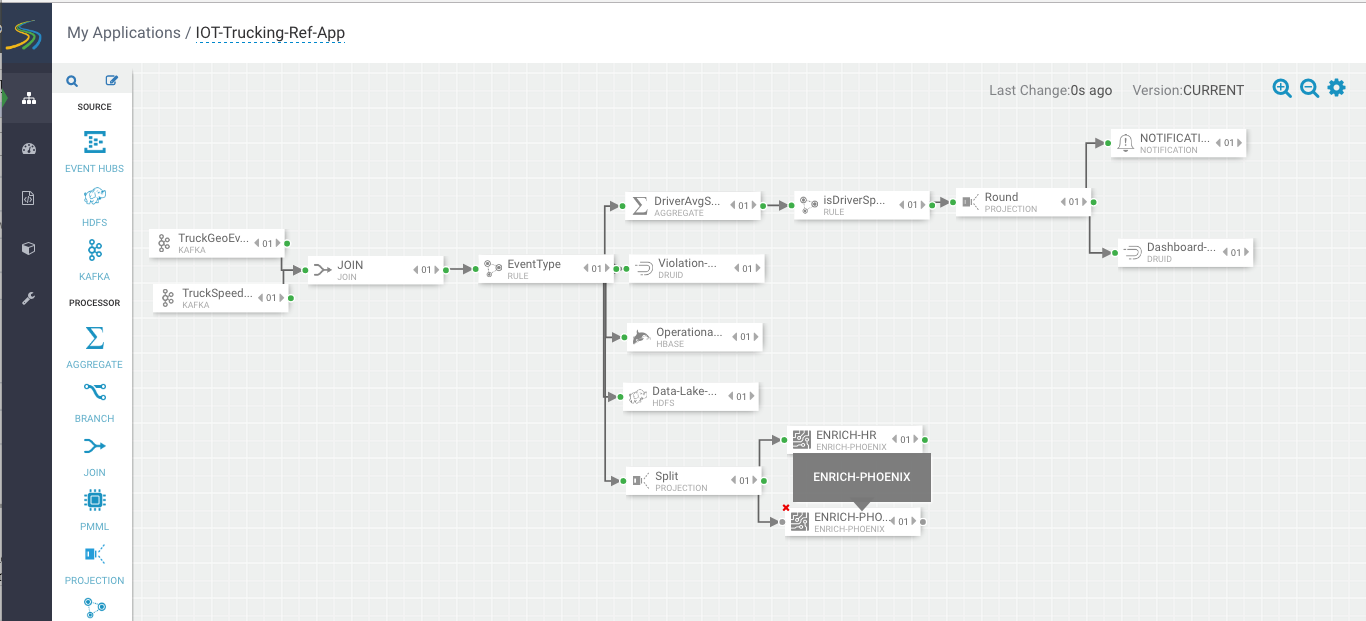
Configure the enrich processor like below. After this processor executes, the output schema will have two fields populated called driverFatigueByHours, driverFatigueByMiles.
ENRICHEMNT SQL: select hours_logged, miles_logged from timesheet where driverid= ${driverId} and week=${week}
ENRICHMENT OUTPUT FIELDS: driverFatigueByHours, driverFatigueByMiles
SECURE CLUSTER: false
INPUT SCHEMA MAPPINGS: Leave defaults
OUTPUT FIELDS: select splitJoinValue, driverFatigueByHours, driverFatigueMiles
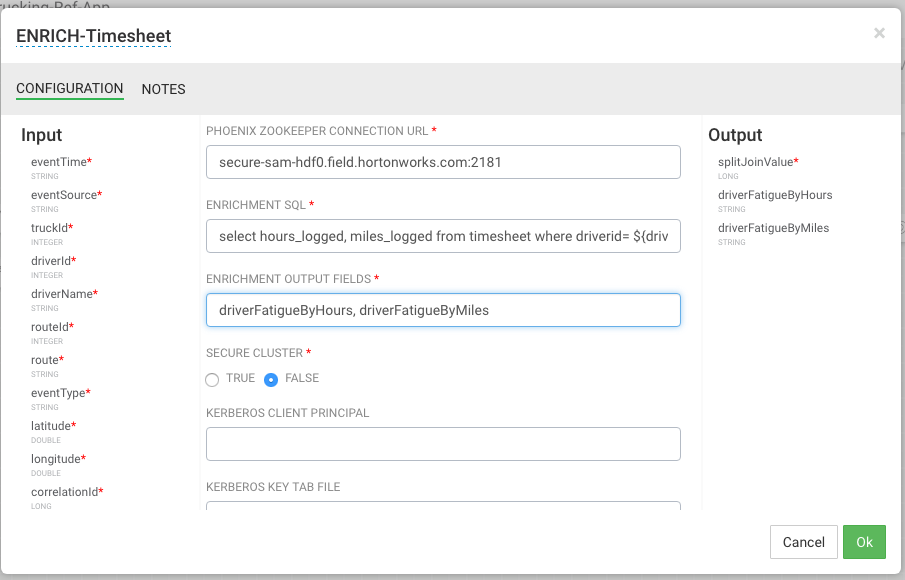
Create the third stream to do weather enrichment by dragging the custom processor we uploaded called "ENRICH-WEATHER" processor to the canvas and connect it from the Split project processor.
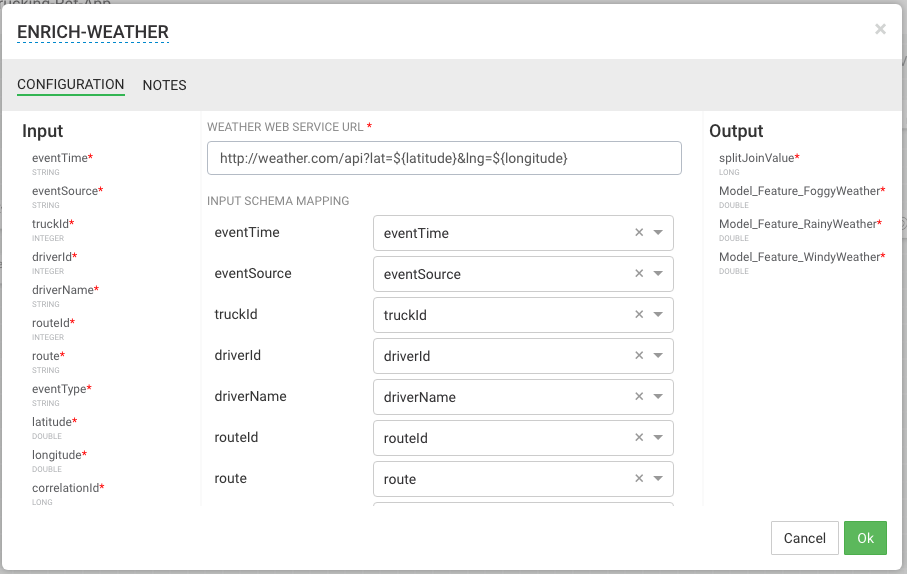
Configure the weather process like the following (currently the weather processor is just a stub that generates random normalized weather info). After this processor executes, the output schema will have three fields populated called Model_Feature_FoggyWeather, Model_Feature_RainyWeather, Model_Feature_WindyWeather.
WEATHER WEB SERVICE URL: http://weather.com/api?lat=${latitude}&lng=${longitude}
INPUT SCHEMA MAPPINGS: Leave defaults
OUTPUT FIELDS: Select the splitJoinValue and the three model enriched features
Steps for Rejoining the Three Enriched Streams
Now that we have done the enrichment in parallel by splitting the stream into 3, we can now join the 3 streams by dragging the join processor to the canvas and connecting the join from the 3 streams.
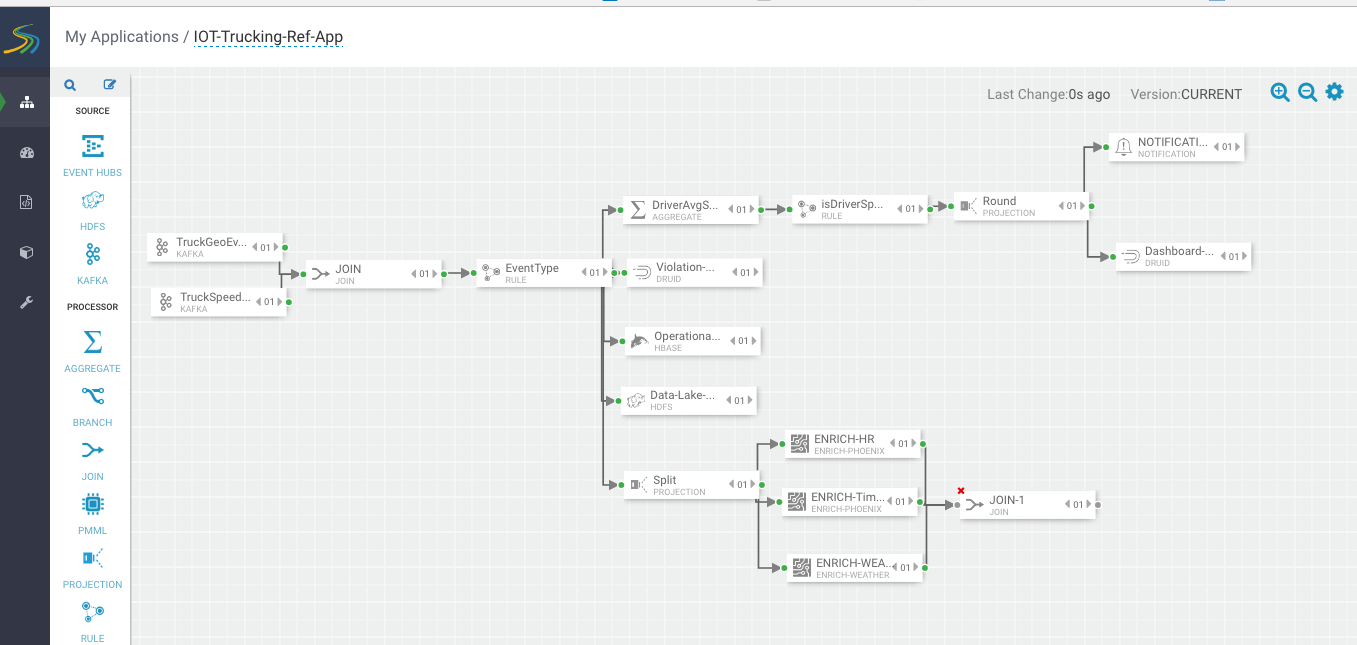
Configure the join processor like the following where we use the joinSplitValue to join all three streams.
For the Output field, just click SELECT ALL to get all the fields across the three streams.
Now that we have joined three enriched streams, lets normalize the data into the format that the model expects by dragging to the canvas the "NORMALIZE-MODEL-FEATURES" custom processor that we added. For the output fields select all the fields and the leave the the mapping as defaults.
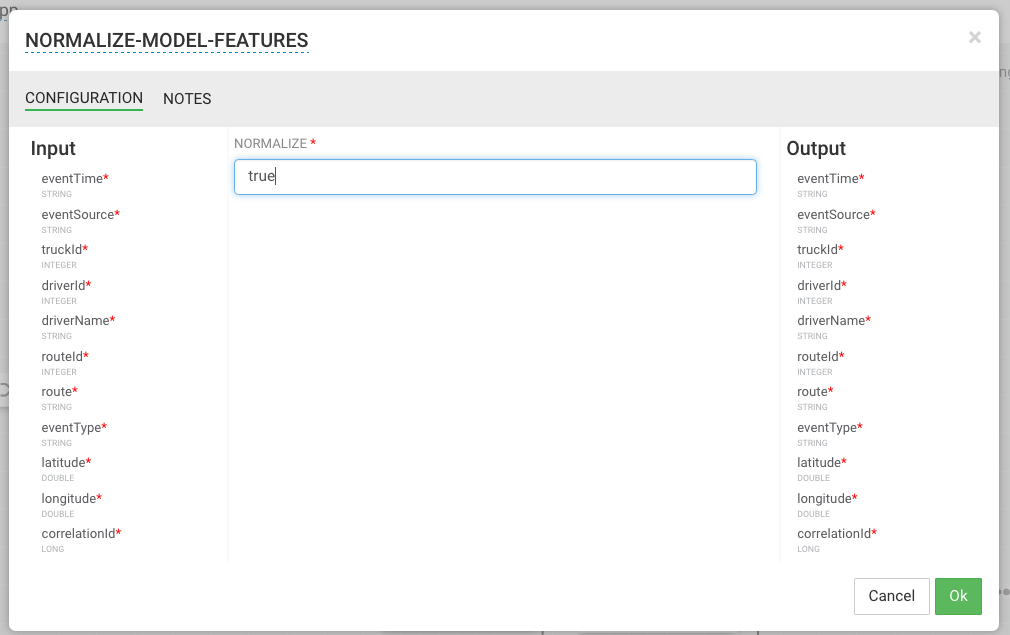
Result
Your flow looks similar to the following.