To add a new data source, you must create a parser that transforms the data source
data into JSON messages suitable for downstream enrichment and indexing by HCP. Although HCP
supports both Java and general-purpose parsers, you can learn the general process by viewing
an example using the general-purpose parser Grok.
- Determine the format of the new data source’s log entries, so you can parse them:
-
Use ssh to access the host for the new data source.
-
View the different log files and determine which to parse:
sudo su -
cd /var/log/$NEW_DATASOURCE
ls
The file you want is typically the access.log, but your
data source might use a different name.
-
Generate entries for the log that needs to be parsed so that you can see the
format of the entries:
timestamp | time elapsed | remotehost | code/status | bytes | method | URL rfc931 peerstatus/peerhost | type
-
Create a Kafka topic for the new data source:
-
Log in to $KAFKA_HOST as root.
-
Create a Kafka topic with the same name as the new data source:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
--zookeeper $ZOOKEEPER_HOST:2181 --create --topic $NEW_DATASOURCE
--partitions 1 --replication-factor 1
-
Verify your new topic by listing the Kafka topics:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --zookeeper $ZOOKEEPER_HOST:2181 --list
-
Create a Grok statement file that defines the Grok expression for the log type you
identified in Step 1.
 | Important |
|---|
You must include timestamp
in the Grok expression to ensure that the system uses the event time rather than
the system time. |
Refer to the Grok documentation for additional details.
- Launch the HCP Management module from
$METRON_MANAGEMENT_UI_HOST:4200, or
follow these steps:
-
From the Ambari Dashboard, click Metron.
-
Select the Quick Links.
-
Select Metron Management UI.
-
Under Operations, click Sensors.
-
Click
 (add) to view the new sensor panel:
(add) to view the new sensor panel:
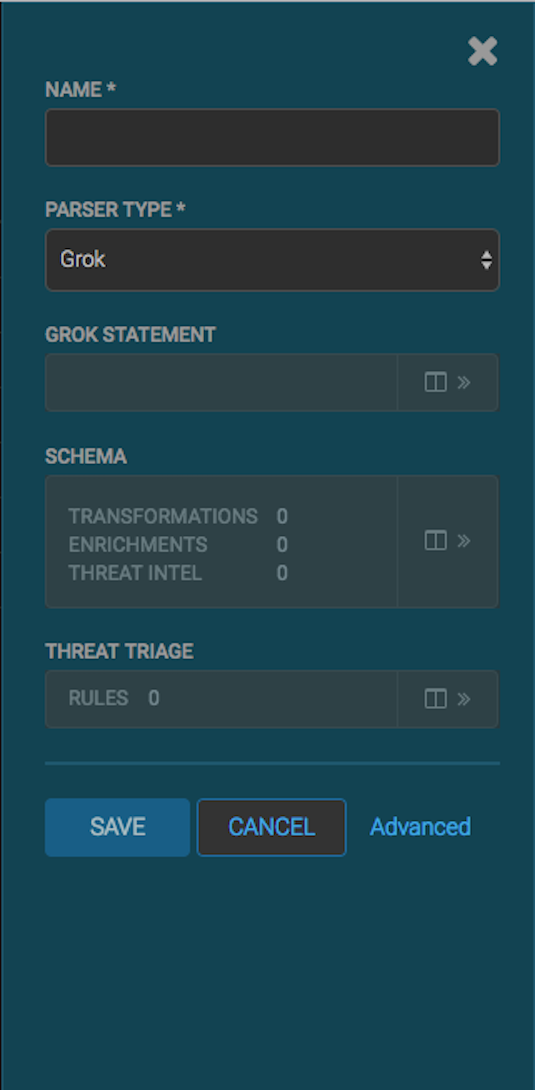
- In the NAME field, enter the name of the new sensor.
Because you created a Kafka topic for your data source, the module should display
a message similar to Kafka Topic Exists. Emitting. If no
matching Kafka topic is found, the module displays No Matching Kafka
Topic.
- In the Parser Type field, choose the type of parser for the new sensor
(in this example task, Grok).
If you chose a Grok parser type and no Kafka type is detected, the module prompts
for a Grok Statement.
-
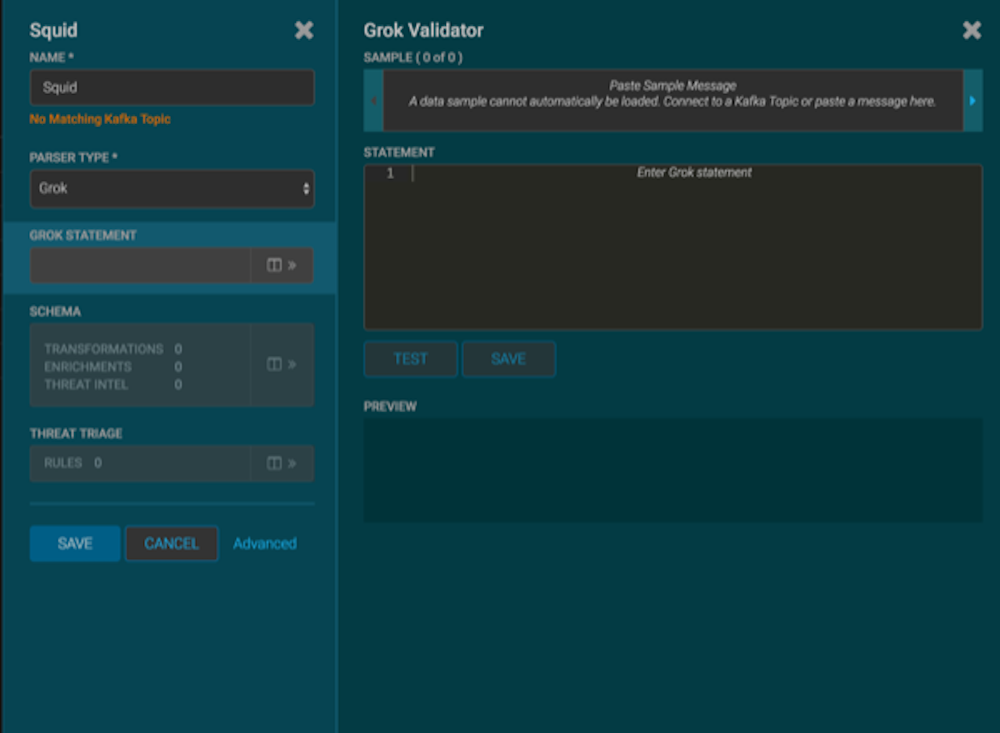
Enter a Grok statement for the new parser:
-
In the Grok Statement box, click
 (expand window) to display the Grok validator
panel:
(expand window) to display the Grok validator
panel:
-
For SAMPLE, enter a sample log entry for the data
source.
-
For STATEMENT, enter the Grok statement you created
for the data source, and then click TEST.
The Management module automatically completes partial words in your Grok
statement as you enter them.
 | Note |
|---|
You must include timestamp to ensure
that the system uses the event time rather than the system time. |
If the validator finds an error, it displays the error information;
otherwise, the valid mapping displays in the PREVIEW
field.
Consider repeating substeps a through c to ensure that your Grok statement
is valid for all sensor logs.
-
Click SAVE.
-
Click SAVE to save the sensor information and add it to the
list of sensors.
This new data source processor topology ingests from the $Kafka topic and then
parses the event with the HCP Grok framework using the Grok pattern. The result is a
standard JSON Metron structure that then is added to the "enrichment" Kafka topic for
further processing.