

Create attached workloads
Once your data lake is running, you can start creating workload clusters attached to the data lake.
Follow these general steps to create an cluster attached to a data lake. In general, once you’ve selected the data lake that the cluster should be using, the cluster wizard should provide you with the cluster settings that should be used for the attached cluster.
Steps
- In the Cloudbreak web UI, click on the cluster tile representing your data lake.
- From the ACTIONS menu, select CREATE ATTACHED CLUSTER.
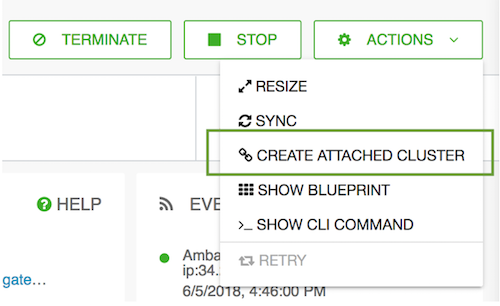
- In general, the cluster wizard should provide you with the cluster settings that should
be used for the attached cluster. Still, make sure to do the following:
- Under Region and Availability Zone, select the same location where your data lake is running.
- Select one of the three default blueprints.
- On the Cloud Storage page, enter the same cloud storage location that your data lake is using.
- On the External Sources page, the LDAP, and Ranger and Hive databases that you attached to the data lake should be attached to your cluster.
- On the Network page, select the same VPC and subnet where the data lake is running.
- Click on CREATE CLUSTER to initiate cluster creation.
As an outcome of this step, you should have a running cluster attached to the data lake. Access your attached clusters and run your workloads as normal.