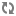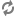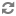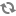In this section:
Tuning parameters for your environment
When the VM starts, the HA Monitor waits for the NameNode to begin responding to file system operations. During this "bootstrap phase”, the HA monitor does not report startup failures of NameNode probes to the HA infrastructure. The HA monitor exits the bootstrap phase once all the probes succeed (from that point, the failure of a probe is reported as a service failure).
The time limit of the bootstrap phase can be configured using the service.monitor.bootstrap.timeout property:
<property> <name>service.monitor.bootstrap.timeout</name> <value>120000</value> <description> The time in milliseconds for the monitor to wait for the service to bootstrap and become available before it reports a failure to the management infrastructure </description> </property>
The timeout must be sufficiently long so that the monitored service is able to open its network ports for external interaction. For the NameNode, the web page and IPC port must be open.
The bootstrap time also needs to include the time required for the HDFS journal replay operations. The bootstrap timeout value should be kept high if the filesystem is large and if the secondary NameNode checkpointing time intervals are longer.
The internal VM Monitor daemon sends “heartbeat” messages to vSphere to indicate that the VM is alive. Use the following property, to modify the rate at which these heartbeats are sent.
<property> <name>service.monitor.report.interval</name> <value>7000</value> <description> Interval in milliseconds for sending heartbeats to vSphere. </description> </property>
It is essential that the live VM sends a heartbeats to vSphere at least every thirty seconds.
A smaller reporting interval reduces the risk of missed heartbeats in case an Operating System or Java related process hangs. However, a smaller reporting interval can also have adverse effects - especially if the VM is overloaded. It is therefore strongly recommended to address the root cause of the VM overload. If your VM is overloaded and becomes unresponsive, we recommend that you either add more CPUs and RAM or rebalance VMs across the cluster.
The Monitor daemon probes the health of the NameNode at a regular interval, and stops sending heartbeats to vSphere when any of the probes fail. Use the following property to change the rate of probes:
<property> <name>service.monitor.probe.interval</name> <value>11000</value> <description> Time in milliseconds between the last probe cycle ending and the new one beginning. The shorter this cycle, the faster failures are detected, but more CPU, network, and server load can be generated. </description> </property>
The smaller the interval between probes, the faster it becomes to detect and report service failures. Although, this might increase the load on the service and the CPU slightly, but even with a very short probing interval, vSphere will not trigger VM restart for at least thirty seconds after the probe failure.
Tuning for NameNode Garbage Collection
The NameNode process can appear hung during Garbage Collection event. To prevent this from triggering immediate failover, a grace period is provided to the NameNode to resume its operation. You can configure this grace period using the following property:
<property> <name>service.monitor.probe.timeout</name> <value>60000</value> <description> Duration in milliseconds for the probe loop to be blocked, before it is considered a liveness failure </description> </property>
A smaller value will cause the VM (where the hung NameNode process is running) faster, but it increases the risk of incorrectly identifying a long GC-related pause as a hung process. On larger clusters (with longer GC pauses), you can increase the value of this property.